技术中心:北京 · 北京东燕郊开发区东方夏威夷U栋
营销中心:北京 · 石景山区北方中惠国际中心D座


技术中心:北京 · 北京东燕郊开发区东方夏威夷U栋
营销中心:北京 · 石景山区北方中惠国际中心D座
北京小程序开发也需要万维网(World Wide Web,简称 WWW 或 Web)并不是互联网本身,而是运行在互联网之上的一套巨大的分布式信息系统。可以把它理解成一座覆盖全球的“数字图书馆”:每一本书就是一个网页,书之间通过超链接互相引用,而我们可以用浏览器随时随地翻阅。
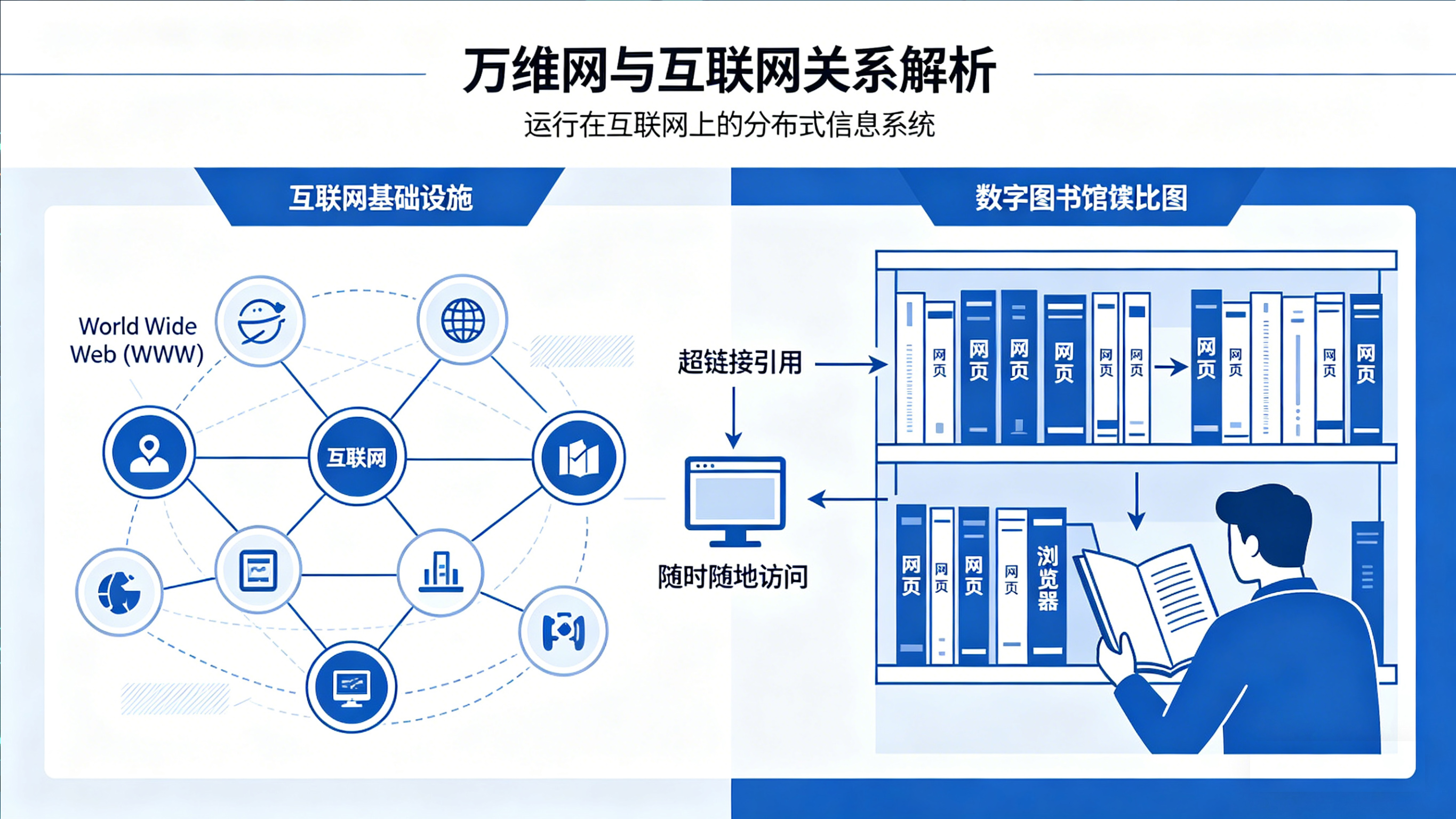
下面我们沿着“在浏览器里输入一个网址并回车”这条主线,来看 WWW 究竟是如何运作的。
你输入的网址,比如 https://www.example.com/index.html,叫做 URL(统一资源定位符)。它拆开来看是这样的:
https – 访问协议,告诉浏览器该怎么说话。
www.example.com – 服务器的域名,相当于图书馆里某台书架的名字。
/index.html – 你具体想看的那个文件的路径。
浏览器拿到这个 URL 后,第一步就是把它分解清楚,知道自己要找谁、要什么东西。
互联网上的设备是靠 IP 地址(比如 93.184.216.34)互相找到对方的,但人类记不住一串数字,所以我们需要用域名。把域名翻译成 IP 地址的服务,就是 DNS(域名系统)。
这个过程很像在手机通讯录里用名字找到电话号码:
浏览器先翻自己的缓存,看最近有没有查过这个域名。
没找到,就问操作系统,操作系统可能也有缓存。
还没有,操作系统就把请求发给 DNS 解析器(通常是你的宽带运营商或公共 DNS,如 8.8.8.8)。
解析器从根域名服务器开始,一级一级问下去(.com → example.com),最终得到 www.example.com 的 IP 地址并返回。
于是,浏览器现在知道要把信寄到哪个“街道门牌号”了。
拿到 IP 地址之后,浏览器需要先和服务器建立一条可靠的连接。
TCP 三次握手
就像打电话时先确认双方都能听见:
“喂,你在吗?” — “在,你听得到我吗?” — “听得到,我们开始聊吧。”
这保证了数据可以按顺序、完整无误地传输。
TLS 握手(当使用 HTTPS 时)
HTTPS 就是穿上了加密外套的 HTTP。在真正的请求发出前,双方还要协商加密算法、交换证书、生成会话密钥。这一步保证了:
你确实在跟真正的 example.com 说话(身份认证);
对话内容被加密,中途谁也看不懂(保密性);
内容没被篡改(完整性)。
现代 WWW 已基本全面使用 HTTPS,所以加密握手是常规环节。
连接建立好以后,浏览器就用 HTTP(超文本传输协议) 这门“通用语言”向服务器发请求。
一个典型的请求长这样:
text
复制
下载
GET /index.html HTTP/1.1 Host: www.example.com User-Agent: Mozilla/5.0 ... Accept: text/html,application/xhtml+xml,... Accept-Language: zh-CN,zh;q=0.9
含义非常直白:
GET 表示“我想要获取一样东西”。
/index.html 是要获取的资源路径。
下面几行是“请求头”,告诉服务器:你是谁(或用啥浏览器)、想要什么格式的内容、接受什么语言等。
如果是登录或填表,还可能在请求里带上一块 请求体(比如用户名密码)。
请求经过互联网送达目标服务器的 Web 服务器软件(比如 Nginx、Apache、IIS 等)。服务器看到请求之后:
找到 /index.html 这个文件,或者把它交给后端的程序(如 PHP、Node.js、Python 等)动态生成内容。
还可能去查数据库、调用其他服务,拼出一份最新的网页。
有时服务器还会检查你带没带 Cookie,识别你的登录状态,然后为你定制内容。
最终,服务器准备好了一份“回复”。
服务器把结果用 HTTP 响应 发回浏览器:
text
复制
下载
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 5234
Set-Cookie: session=abc123; Path=/
<html>
<head><title>示例页面</title></head>
<body>
<h1>欢迎访问 WWW!</h1>
...
</body>
</html>
第一行的 200 OK 是状态码,表示一切顺利(常见的还有 301 重定向、404 没找到、500 服务器错误等)。
后面的头部告诉浏览器:我给你的是 HTML 文本、有多长、要不要给你种个 Cookie 之类的。
空行后面就是 响应体,也就是网页的 HTML 源代码本身。
拿到 HTML 只是万里长征走完一半。浏览器现在要把它从一堆代码变成视觉化的网页。这个过程叫 渲染:
解析 HTML,构建 DOM 树
HTML 描述的是页面结构。浏览器逐行解析,把它变成一棵“文档对象模型树”(DOM),就像搭出房子的骨架。
解析 CSS,构建 CSSOM 树
遇到 <link rel="stylesheet"> 或 <style>,就去下载并解析 CSS,形成样式规则树。它决定了骨架长什么样子:颜色、大小、位置等。
执行 JavaScript
遇到 <script>,JavaScript 代码会运行,可以动态修改 DOM 和 CSSOM,让页面动起来、响应你的操作。
生成渲染树并布局
DOM 和 CSSOM 合并成渲染树,然后计算每个元素的确切位置和尺寸(布局/回流)。
绘制与合成
最后一步步画到屏幕上:填色、上字、贴图、加阴影……最终变成你眼前活灵活现的页面。
HTML 页面通常还会引用其他资源:CSS 文件、JS 脚本、图片、字体、视频等。浏览器一边解析一边发现这些 URL,就会再次重复前面的步骤:
对每个资源都可能需要 DNS 查询(通常已缓存)、建立连接(可能复用现有通道),用 HTTP/HTTPS 获取它们。
现代浏览器会尽量并行下载,以加快整体速度。HTTP/2 和 HTTP/3 更允许在一条连接上同时收发多个请求,大幅提升效率。
等你看到一个完整、排版精美、能点击互动的网页时,背后其实已经飞速跑完了数百次甚至上千次网络请求与计算。
从整个流程可以看出,WWW 由三项核心技术支撑,缺一不可:
URL(统一资源定位符):回答“东西在哪里”;
HTTP(超文本传输协议):回答“怎么拿、怎么传”;
HTML(超文本标记语言):回答“页面怎么做出来、怎么链接到别的页面”。
这三者再加上遍布全球的服务器、浏览器软件和负责寻路的互联网基础设施,就构成了可以不断点击、跳转的“世界之网”。
无状态但可以“记住你”
HTTP 协议本身是“无状态”的,每个请求都是独立的,服务器默认不记得你上次来过。而那些“已登录”的体验,是靠 Cookie 或 Token 等机制在每次请求时悄悄带上一段身份标记来实现的。
分布式的、去中心化的
没有一条“中央总线”去管理所有网页。任何人都可以架设自己的 Web 服务器,连接入互联网,再通过超链接和别人互相引用,WWW 因此疯狂生长。
不断进化的传输
从 HTTP/1.0 到 1.1(长连接),再到 HTTP/2(多路复用),再到基于 UDP 的 HTTP/3,每一次升级都让页面加载更快、更安全。现在你访问的绝大多数网站,都已经在背后无缝使用了这些新技术。
总结一下:WWW 的工作原理,本质上就是全球无数客户端与服务器之间用标准化的语言(HTTP)交换用超文本(HTML)写成的页面,并依靠 URL 和 DNS 精准定位彼此。 你每点一次链接,整个世界就有无数计算机和网络设备在一瞬间协同工作,把你想要的那一“页”千里迢迢送到眼前。

扫一扫,有惊喜
微信扫一扫,联系智禧科技




